

天気情報を表示する2(スマート編)
基本編では、天気情報をサーバーから取得し、その情報から現在の天気を抜き出すところまで紹介しました。
しかも、かなり力技の方法で紹介しました。
これだけ知っておけば何とかなる方法なので、このまま拡張して行くのもアリなのですが、やはりプログラムは美しくなければなりません。
後から修正しようとした時に全然分からないと、時間が勿体ないだけなので、極力プログラムは美しく記述しましょう!
今回は、基本編を拡張する前に、基本編をスマートにします。
情報の抜き出し方を見直す
実際に基本編をやった方なら、心底感じたことだと思いますが、いちいち数えていられません。
いくらプログラムを組むためとは言え、やってられません。
現在の天気1つ抜き出すだけでも面倒なのに、都市名や気温などもやろうと思うと、さらなる覚悟が必要になってしまいます。(単純作業ですからね・・・)
取得する情報によっては、内容がもっと細かかったり、週間天気などもあるので、気が遠くなってしまいます。
それは、いちいち数えなければならないからですね。
どうせプログラムを組むならプログラムで数えれば良いぢゃん!!ということで、取得した天気データから目的のノードが何番目か数える関数を作りましょう!
このサイトの特徴として、「いきなりやってみる」というパターンが多々ありますが、ここではムリなのでやりません。
どちらかと言うと、しっかり方向性を見極めて、慎重に進めるべき内容なので、考え方からまとめていきます。
考え方
入れ子になっているので、数える範囲に気を使わなければなりませんが、目的のタグに向かってひたすら数えました。
特に、<channel>内の<item>は、0から25まで数えました。
数える時を思い返してみて下さい。
私だけかもしれませんが、指でタグを指し、0から順に数えながら指をズラし、<item>の所に行くまで数えたはずですよね?
まさに、そのやり方をプログラムにします。
子ノード探索関数
で、作った関数がこちらです。
var i;
for(i=0;i<element.childNodes.length;i++){
if (child.nodeName == nodeName) return i;
}
}
findChildという関数です。
elementとnodeName引数とし、elementの中のnodeNameと一致する時の番号を返す関数となっております。
iをローカル変数とし、ループを回します。
elementの子ノード総数だけ回します。
回しながら、ループ内で参照している子ノードのノード名と、目的のノード名が一致した時のローカル変数iを、関数の戻り値としています。
実際は、何も引っかからずにループを抜けてしまった時などの対策もしていますので、ぜひソースを確認してみて下さい。
子ノード探索関数の使い方
作った関数の使い方ですが、プログラムで数えさせるので、数えるための材料を用意し、出てきた番号で基本編の記述を書き換えるだけです。
数えるための材料は2つあります。
「どこで数えるのか」と、「どこまで数えるのか」です。
最初は取得したXMLの頭から数えますので、サンプルではrequest.responseXMLを数えます。
サンプルでは、初めに"rss"から探したので、"rss"まで数えます。
この2つの材料を、作った関数に放り込んでやると、以下のような書き方になります。
このように書くことで、request.responseXML内に"rss"というタグが何番目に出てくるかを数字で得ることができます。
そして、その数字を、サンプルではnum_rssに格納しています。
このnum_rssを使うと、"rss"の子ノードは以下のように記述して取得することができます。
これで、基本編の記述を書き換えることができました。
しかも自分で数えることなく書き換えることができたのです。
実際に数えた人にとっては、大きな前進ですね。
サンプルでは、この子ノードをelm_rssに格納しています。
実際の呼び出し関数
作った関数の使い方を学んだので、実際にこの関数を呼び出す関数を完成させます。
基本は、さきほどの使い方の通りです。
XMLの入れ子に沿って、数えるための材料が変わることに注意すれば、何の問題もありません。
呼び出す関数は、基本編においてXMLの読み込みが完了した時に、データを表示した関数であるxml_responded (request)です。
この関数xml_responded (request)は以下の通りです。
var num_rss = findChild(request.responseXML, "rss");
var elm_rss = request.responseXML.childNodes(num_rss);
var num_channel = findChild(elm_rss, "channel");
var elm_channel = elm_rss.childNodes(num_channel);
var num_item = findChild(elm_channel, "item");
var elm_item = elm_channel.childNodes(num_item);
var num_yweather_condition = findChild(elm_item, "yweather:condition");
var elm_yweather_condition = elm_item.childNodes(num_yweather_condition);
var weather = elm_yweather_condition.getAttribute("text");
document.getElementById("data").innerText = weather;
}
上から見てみて下さい。
"rss"が出てくる順番を特定したら、その番号で"rss"の子ノードを取得します。
今度は、その"rss"の子ノードで、"channel"が出てくる順番を特定し、子ノードを取得します。
これを繰り返し、最後に"text"を取得する所で、基本編の書き換えが完了します。
実際に実行しても、変化がないのは当たり前なので、本当に数を数えているのかを確認してみました。
SafariのWebインスペクタでのスクリーンショットです。
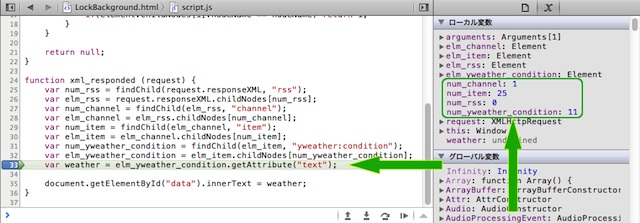
天気のテキストを抜き出す所で止まっているのですが、その右側に順番が取得できていることを確認して下さい。
サンプルのダウンロードはこちら ー> wf_21のダウンロード
サンプルのブラウザ表示はこちら ー> wf_21の表示
情報の抜き出し方をもっと見直す
いちいちタグを数える必要はなくなりました!
しかし、ソースは美しいでしょうか?
必要だとは言え、ダラダラと長くなっているし、結局は基本編を書き換えただけであって、スマートではありません。
もっと見直しましょう!!
考え方
ソースをじっと眺めてみて下さい。
私もじっと眺めてみたのですが、なぜ美しくないか分かりました。
「二度手間」が存在しているのです。
確かに、プログラムで数えたから、そのまま基本編を書き換えることができました。
しかし、数えるときの工程にムダがあるのです。
子ノードを参照して、nodeNameが一致した時の順番を返していましたね。
そして、その順番でまた子ノードを参照しました。
どうせ子ノードを参照するなら、子ノードを返せば良くないですか?
そうすることで、ムダが省けますね!!
新・子ノード探索関数
で、作り直した関数がこちらです。
var child;
for(child = element.firstChild; child != null; child = child.nextSibling){
if (child.nodeName == nodeName) return child;
}
}
基本は同じですが、番号でループさせるか、子ノードでループさせるかが違います。
子ノードでループさせられるのかが疑問かと思いますが、次のインターフェースで解決します。
firstChild
その名の通り、「最初の子」を特定できます。
nextSibling
「次の子ノード」を特定できます。
これらの子ノードに関するインターフェースを使うことで、子ノードのループが実現します。
"firstChild"でループをスタートし、何もない状態の"null"になるまで、"nextSibling"を繰り返します。
新・子ノード探索関数の使い方
こちらも基本は同じです。
中身が、番号ではなく子ノードでループしているので、探索後の参照が不要になります。
しかし、用意する材料は変わらず、「どこで」と、「どこまで」の2つを用意します。
この2つの材料を、作った関数に放り込んでやると、サンプルでは、以下のような書き方になります。
ホントに、何も変わっていませんね。
最大の違いは、「これで終わり」ということです。
かなりの手間が省けましたね。
実際の呼び出し関数
実際の呼び出し関数も、参照する必要がなくなったので、ムダが省けます。
サンプルは、以下の通りです。
var elm_rss = findChild(request.responseXML, "rss");
var elm_channel = findChild(elm_rss, "channel");
var elm_item = findChild(elm_channel, "item");
var elm_yweather_condition = findChild(elm_item, "yweather:condition");
var weather = elm_yweather_condition.getAttribute("text");
document.getElementById("data").innerText = weather;
}
参照しなくても良いので、ソースが半減しましたね。
スマートになったサンプルを用意しました。
サンプルのダウンロードはこちら ー> wf_22のダウンロード
サンプルのブラウザ表示はこちら ー> wf_22の表示
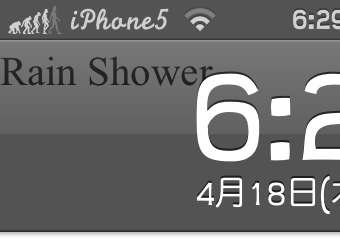
基本編の最後にも表示したロック画面のスクリーンショットです。
今回は、フォントサイズを指定し、位置もズラしたので、見やすくはなりました。
取得確認だけなので、これでOKとします。
それにしても、"Rain Shower"って・・・
冷たい雨なんでしょうね。
情報の抜き出し方をもっともっと見直す
いちいちタグを数える必要もなくなり、二度手間も省きました。
では、ソースは美しくスマートなものになったでしょうか?
この辺から、判断が分かれると思います。
私の判断でも、満点ではありませんが、十分合格点には達しています。
でも、もっと簡略化することはできます。
もっともっと見直しましょう!!
考え方
また、ソースをじっと眺めてみましょうか。
実際の呼び出し関数(xml_responded)に、前回と同じような「二度手間」が存在しています。
これを「手間」と思うかどうかが分かれ目なのですが、子ノードを特定したら、それを要素変数(elm_rssなど)に格納していますよね?
そして、その要素変数で、また子ノードを特定しています。
今回は、この「二度手間」を省きます。
何かを見ている人を見てる人・・・を見てる人・・・を見てる人・・・という感じです。
実際の呼び出し関数
サンプルは、以下の通りです。
var weather = findChild(findChild(findChild(
findChild(request.responseXML, "rss"), "channel"), "item"),
"yweather:condition").getAttribute("text");
document.getElementById("data").innerText = weather;
}
見事に1つになっています。
実際には、改行はありません。
分かれ目のポイントとなるのが、この見た目なのです。
見にくいと思う方は、ここまでやる必要はないと思います。
ただ、赤い文字の部分のように、特にポイントとなるキーワードが並んだ状態になるので、プログラム的には「見やすい」という判断もできます。
サンプルのダウンロードはこちら ー> wf_23のダウンロード
サンプルのブラウザ表示はこちら ー> wf_23の表示
情報の抜き出し方をもっともっともっと見直す
あれだけあったソースが、かなり簡略化されました。
この先はムリだと思っている方も、すでに気付いている方も、お待たせ致しました!!
題して、「これでもか編」です。
どうせなら、全部まとめてしまえ!ということです。
先に言っておきますが、ここまでやる必要はありません。
考え方
全部まとめます。
実際の呼び出し関数
サンプルは、以下の通りです。
document.getElementById("data").innerText = findChild(findChild(findChild(
findChild(request.responseXML, "rss"), "channel"), "item"),
"yweather:condition").getAttribute("text");
}
あれだけあったソースが、1行に収まっています。
サンプルのダウンロードはこちら ー> wf_24のダウンロード
サンプルのブラウザ表示はこちら ー> wf_24の表示
情報の抜き出し方をもっともっともっともっと見直す
さすがにもうムリだと思っている方!!
その通りです。もしあったとしても、これ以上はやりません。
どちらかと言うと、見直したことを見直すべきだと思います。
私が思う満点は、簡略化する前と、簡略化した後の間にあると思います。
それは、取得したデータに柔軟に対応できる状態のことを言います。
せっかく、数えなくても良いように作った関数ですが、簡略化をし過ぎて、Yahooウェザーの現在の天気しか表示できないものになってしまいました。
とても、これを「柔軟である」とは言えません。
この先、どんどん拡張していく予定ですが、扱うデータやそれを表示するレイアウトなどを踏まえたプログラミングを考えていきましょう。
スマートの意味は「スリム」ではありませんからね。
柔軟なプログラムほど、とても美しいですよ。
皆さんが「美しい」と思えるようなサンプルを、私もがんばって作っていきます。